
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие:
• сбор - накопление информации с целью обеспечения достаточной полноты для принятия решений;
• формализация - приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
• фильтрация - отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
• сортировка - упорядочение данных по заданному признаку с целью удобства использования; эта процедура повышает доступность информации;
• архивация - организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
• защита - комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
• транспортировка - прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя - клиентом; • преобразование данных - перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных. В качестве примера можно упомянуть, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства - телефонные модемы.
Приведенный здесь список типовых операций с данными далеко не полон. Миллионы людей во всем мире занимаются созданием, обработкой, преобразованием и транспортировкой данных, и на каждом рабочем месте выполняются свои специфические операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный список возможных операций составить невозможно, да и не нужно. Сейчас нам важен другой вывод: работа с информацией может иметь огромную трудоемкость, и ее надо автоматизировать.
Процедура доступа к данным может быть инициирована как самим компьютером (для решения каких-либо своих технических задач), так и конечным пользователем. В последнем случае пользователь формирует запрос, куда включает, в частности, обозначение требуемого вида доступа или действия и указание на то, над какими данными это действие надо выполнить. Как отмечалось ранее, идентификация данных осуществляется с помощью ключей. В качестве же требуемого действия может производиться одно из следующих: добавление, удаление, изменение, просмотр элемента или обработка данных из элемента.
При добавлении элемента информационный массив пополняется новыми данными в виде записи файла или файла в целом, соответственно, для структурированных и неструктурированных данных. В запросе в этом случае, помимо указанной выше информации, приводится и сам новый элемент. При этом объем информационного массива увеличивается.
Удаление, наоборот, является обратным действием, вызывающим исключение упомянутых данных. Это действие приводит к уменьшению объема информационного массива.
Изменение относится не к элементу, а к его составляющим – полям записи файла или тексту, хранящемуся в файле, и означает, в свою очередь, удаление прежних значений полей или строк текста и/или добавление новых. В запрос включается дополнительная информация, указывающая на требуемые составляющие изменяемого элемента, а также сами новые значения этих составляющих. Объем информационного массива при этом не меняется для структурированных данных и, возможно, меняется для неструктурированных;
Просмотр связан с предоставлением данных пользователю на устройстве вывода компьютера, как правило, на дисплее. В запросе в этом случае дополнительно указывается, какие составляющие элемента требуется просмотреть (по умолчанию просматривается весь элемент).
Обработка предусматривает выполнение некоторых арифметических операций над данными элемента, например, накопление суммы и т.д., и относится только к структурированным данным, а потому далее не рассматривается.
Чтобы выполнить любое их указанных выше действий, нужный элемент должен быть предварительно найден в информационном массиве, для чего выполняется его поиск (для добавления нового элемента тоже делается попытка его поиска, которая заканчивается неудачно, и тогда элемент добавляется). Под поиском элемента понимается определение его местонахождения в информационном массиве. Таким образом, любой доступ включает поиск, что делает эту фазу доступа наиболее значимой.
Технологии доступа при выполнении действий изменения элемента показана на рис. 79.
Здесь и далее сплошные линии означают управляющие связи, пунктирные - информационные связи.
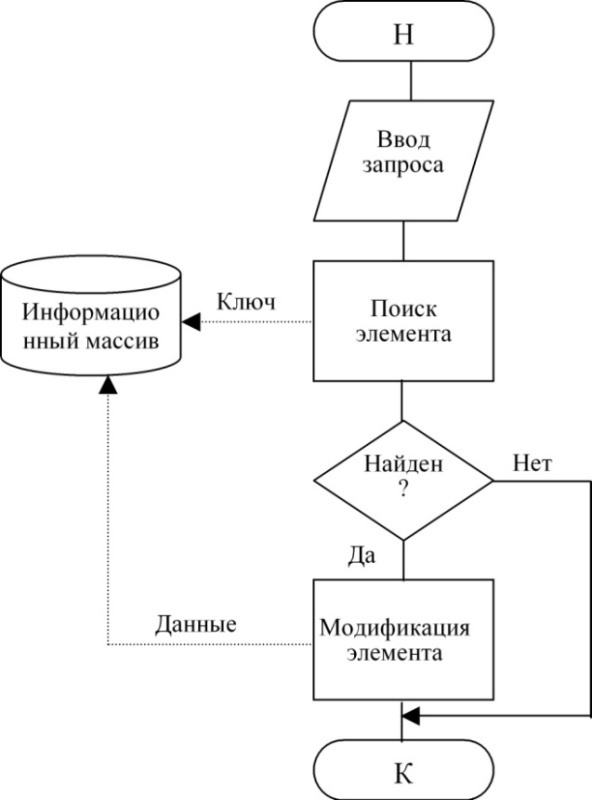
Рисунок 79. Технологии доступа при выполнении действий изменения элемента
Технологии доступа при выполнении действий добавления элемента показаны на рис. 80:
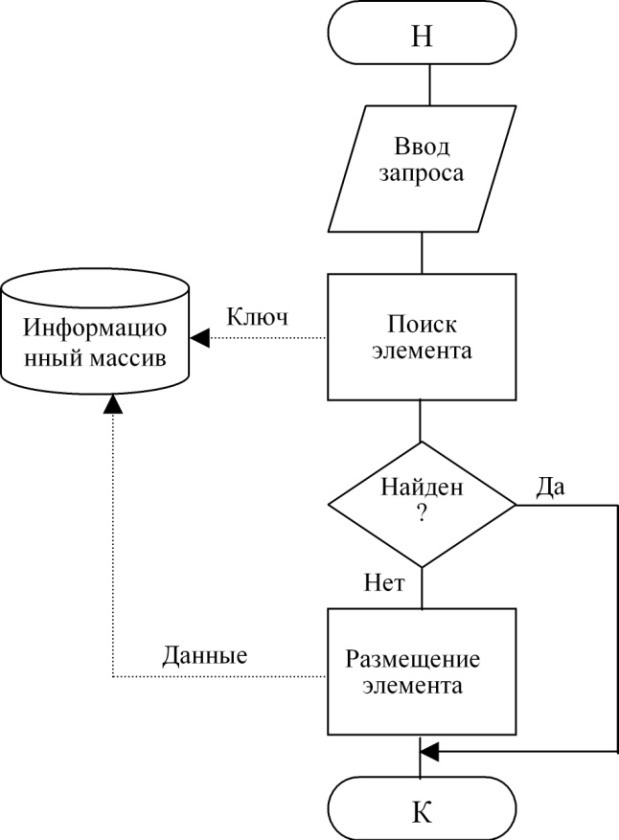
Рисунок 80. Технологии доступа при выполнении действий добавления элемента
Технология удаления изображена на рис. 81.
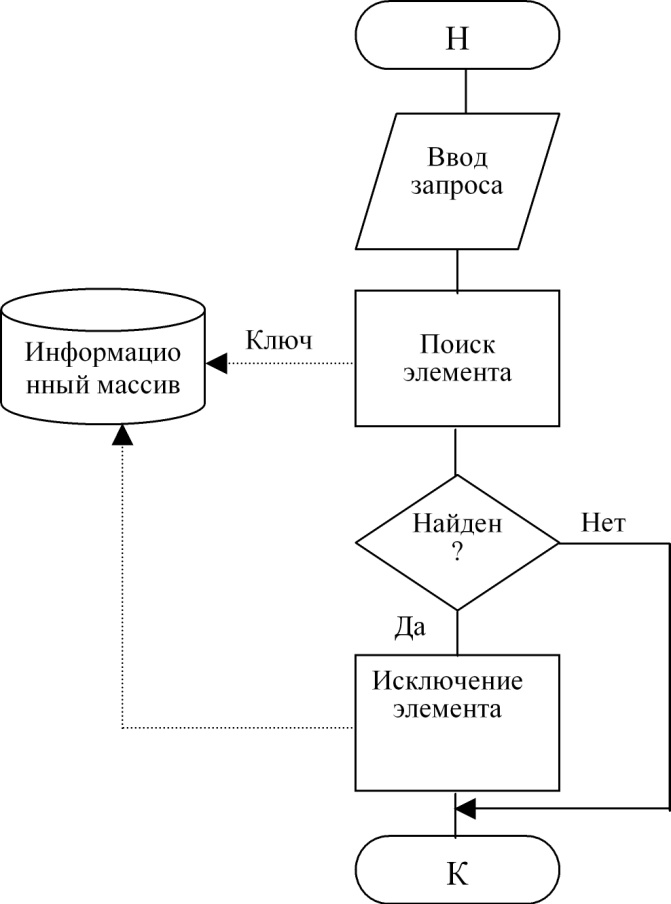
Рисунок 81. Технология удаления элемента
Технология просмотра элемента приведена на рис. 82. Различие в схемах состоит в том, что по технологии рис. 79 и 80 выполняется воздействие на информационный массив с целью его изменения, для чего в него передаются данные, по технологии рис. 81 воздействие не связано с передачей данных, а по схеме рис. 82 данные выводятся из информационного массива без его изменения.
При выполнении рассмотренных действий над элементами информационного массива на практике важны два фактора, противоречащие друг другу: временной фактор, в соответствии с которым запрос пользователя должен обрабатываться в минимальные сроки, и фактор минимизации требуемого объема памяти для хранения данных.
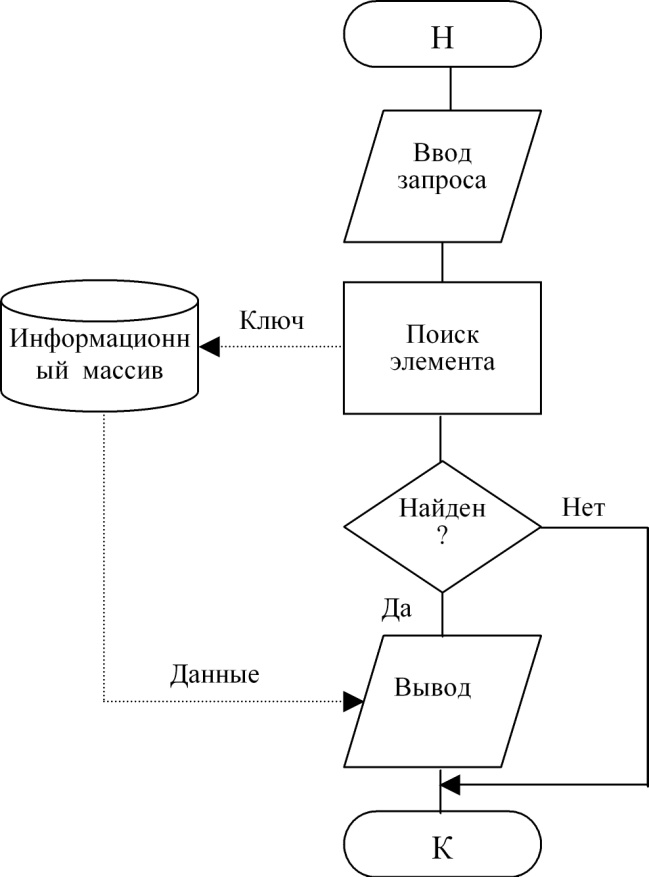
Рисунок 82. Технология просмотра элемента
Для уменьшения времени обработки запроса особые усилия прилагаются к применению таких структур хранения данных, которые позволяли бы оптимизировать поисковые операции, возможно, за счет дополнительных описаний данных. Это, очевидно, повышает расход памяти. Поэтому при проектировании моделей данных учитывается предполагаемый режим эксплуатации информационного массива: если это интерактивный режим, то основное внимание уделяется минимизации времени доступа к данным, если же режим пакетный, то минимизируют требуемую память. Кроме того, на выбор модели влияют особенности той предметной области, которая отражается в структурах хранения.
В силу вышесказанного, основное внимание в данном разделе уделено задачам организации хранения данных разных видов и поиска по ключам, входящим в запросы пользователей, поскольку поисковые операции и определяют, в основном, продолжительность различных действий над информационным массивом. Из приведенных типов действий в рассмотрение включены добавление и просмотр элементов данных, поскольку добавление связано с воздействием на информационный массив и изменением его объема (напомним, что удаление является обратным действием по отношению к добавлению), а просмотр - это наиболее часто выполняемые действия на практике. При этом рассматриваются общие вопросы работы с текстовой и структурированной информацией, методы и модели, используемые при организации хранения, поиска и добавления данных.
Излагаемые модели данных и алгоритмы доступа к ним составляют “brainware” современной информатики, носят универсальный характер и применяются в большинстве систем, связанных с хранением и обработкой информационных массивов.
Индексирование
Одна из основных задач, возникающих при работе с базами данных, – это задача поиска. При этом, поскольку информации в базе данных, как правило, содержится много, перед программистами встает задача не просто поиска, а эффективного поиска, т.е. поиска за сравнительно короткое время и с достаточно большой точностью. Для этого (для оптимизации производительности запросов) производят индексирование некоторых полей таблицы. Использовать индексы полезно для быстрого поиска строк с указанным значением одного столбца. Без индекса чтение таблицы осуществляется по всей таблице, начиная с первой записи, пока не будут найдены соответствующие строки. Чем больше объем таблицы, тем выше накладные расходы. Если же таблица содержит индекс по рассматриваемым столбцам, то база данных может быстро определить позицию для поиска в середине файла данных без просмотра всех данных. Это происходит потому, что база данных помещает проиндексированные поля поближе в памяти, так, чтобы можно было побыстрее найти их значения. Для таблицы, содержащей 1000 строк, это будет как минимум в 100 раз быстрее по сравнению с последовательным перебором всех записей. Однако в случае, когда необходим доступ почти ко всем 1000 строкам, быстрее будет последовательное чтение, так как при этом не требуется операций поиска по диску. Так что иногда индексы бывают только помехой. Например, если копируется большой объем данных в таблицу, то лучше не иметь никаких индексов. Однако в некоторых случаях требуется задействовать сразу несколько индексов (например, для обработки запросов к часто используемым таблицам).
Если говорить о MySQL, то там существует три вида индексов: PRIMARY, UNIQUE, и INDEX, а слово ключ (KEY) используется как синоним слова индекс (INDEX). Все индексы хранятся в памяти в виде B-деревьев.
PRIMARY – уникальный индекс (ключ) с ограничением, устанавливающим, что все индексированные им поля не могут иметь пустого значения (т.е. они NOT NULL). Таблица может иметь только один первичный индекс, который может состоять из нескольких полей.
UNIQUE – ключ (индекс), задающий поля, которые могут иметь только уникальные значения.
INDEX – обычный индекс (как описано выше). В MySqL, кроме того, можно индексировать строковые поля по заданному числу символов от начала строки.
| < Предыдущая | Следующая > |
|---|